EC2上でAPIを定期的に動かして取得したデータをRDSに保存します。またそのデータをFlaskでWebアプリとして表示していきます。
(1) APIの動作確認
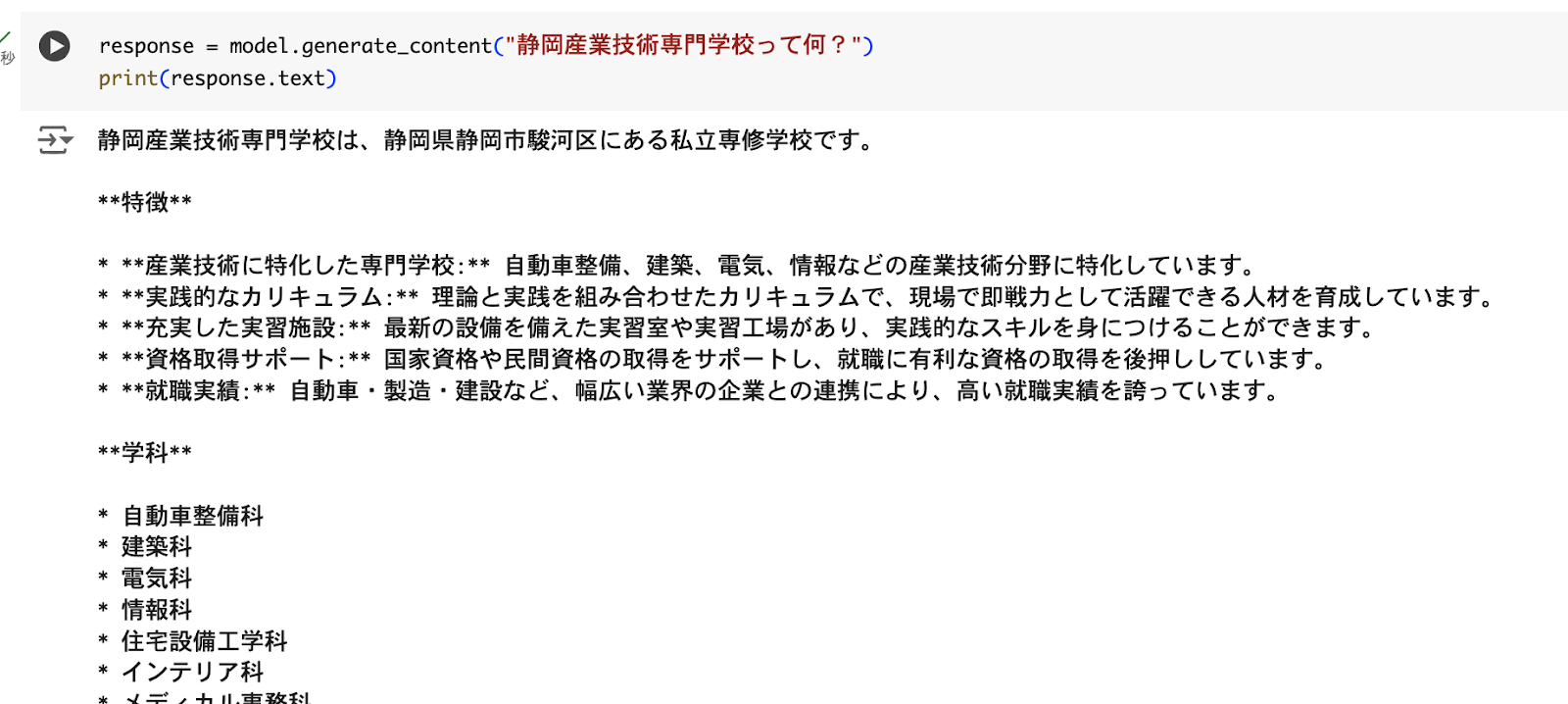
利用するAPIは、International Space Station Current Location (http://open-notify.org/Open-Notify-API/ISS-Location-Now/) で国際宇宙ステーションの現在位置を返してくれます。まずPostmanで実行してみます。指定されたURLを入力するだけです。
Pythonコードへ変換すると、次のようになります。
APIの動作確認ができました。もう少し、キレイなコードにして、時刻も秒までわかりやすく表示します。
(2) EC2上で取得できるようにする
次にEC2上でAPIを取得できるようにします。
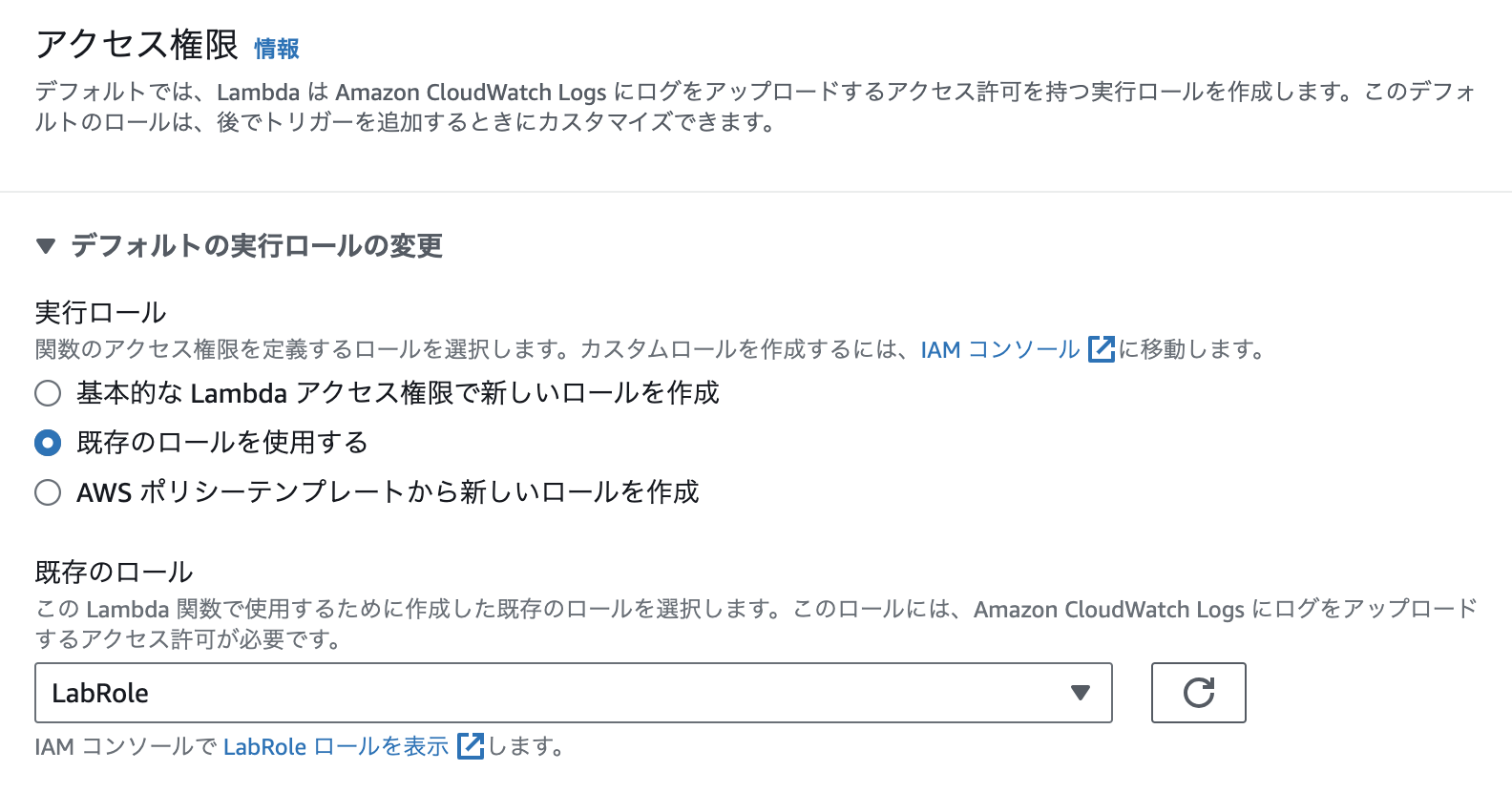
EC2の立ち上げは下記を参照してください。
今回は「ec2-user」のままで実施します。pythonはインストールされていますがpipがありませんので、pipをインストールしてください。
$ sudo yum install python3-pip
Pythonファイルを作成して、(1)で実施したプログラムを動かしてみます。ファイル名は「iss_api.py」とします。
$ python3 iss_api.py
(3) データベースの用意
今回はAWS RDSをCloud Shellから使います。下記を参考にしてください。
同じEC2上で、MySQLを動かして実施することも可能です。その場合は下記を参考にしてください。
MySQLで実施する場合、GPG-KEYの更新を忘れないようにしてください。
sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2023
データベース、テーブルの作成をしていきます。
データベース名:iss、テーブル名:point で作成します。
RDS(またはMySQL)に接続し、SQL文を発行します。
(4) EC2上のPythonプログラムからデータベースへ情報の格納
次に国際宇宙ステーションのAPIを使って情報を取得し、データベースに格納していきます。下記を参考にしてください。
MySQL Connectorのインストール:pip install mysql-connector-python
MySQL Connectorのインストールを行い、次のプログラムを実行します。プログラム名は「iss_api_db.py」とします。MySQLのhostはRDSを使っている場合は、エンドポイントを利用します。MySQLをEC2上にインストールした場合は、localhostのままです。
$ python3 iss_api_db.py
select文でテーブルを確認すると、データが格納されているのがわかります。
(5) プログラムの定期実行
cronを使って、1分に1回定期実行していきます。まず、cronieをインストールします。
$ sudo yum install cronie
$ sudo systemctl start crond
$ sudo systemctl enable crond
ターミナルでcrontab -eコマンドを実行し、crontabの編集を開始します。
$ crontab -e
書き込む内容
* * * * * /usr/bin/python3 /home/ec2-user/iss_api_db.py
$ chmod +x iss_api_db.py
データベースを確認すると1分毎格納されていることがわかります。
(6) Flaskを使って、最新5件のpoint情報を地図上に表示する
Flaskを使って、pointテーブルにある最新5件の情報を地図上に表示します。
Flaskのインストール
$ pip install Flask
上記の参考リンクと同様に以下のようにディレクトリ構成を作成します。
iss_app/
├── app.py
└── templates/
└── index.html
app.py
index.html
注意:
Flaskはデフォルトポート5000なので、セキュリティグループからインバウンド設定に5000ポートを許可する。
$ python3 app.py
今回はテスト用なので「http」でアクセスしています。ブラウザによっては、デフォルトが「https」なので接続時にエラーになる可能性もあります。
ここまでの内容で、APIで定期的に取得した内容をDBに格納し、それをWebアプリとして表示することができました。
注意:
cronに関しては、
$ crontab -e
で開き、対象行を削除するか、コメントアウト(#をつける)をしてください。